Inhaltsverzeichnis
Übungen
Aufgabe 2
Anwenderprogramme laufen im user-Mode, im Systemmodus sind nur previligierte Aufrufe erlaubt,. Systemaufrufe (Syscalls) dienen als Schnittstelle zum BS.
Bsp.: Datei öffnen, Dateiattribute abfragen
Implementiert heutzutage durch Software Interrupts, damals durch feste Adressen
Jeder Syscall hat feste ID, Anwndungsprogramm legt diese ID + Aufrufparameter in bestinteb Registren ab und sendet Interrupt. BS checkt diese Register und führt dann Syscall aus.
Aufgabe 3 b)
strace zeigt die Systemaufrufe an, die ein Aufruf durchführt
strace -c <Aufruf der angezeigt werden soll>
Aufgabe 3 c)
Bei ls werden nur die Dateien die an sich betrachtet, bei ls -la auch noch die versteckten Dateien.
Aufgabe 3 a)
mult(2, 3) → mult(1, 3) → mult(0, 3)
Aufgabe 3 b)
Register, Rücksprungadresse, Parameter, Ergebnis
Aufgabe 3 c)
- Prolog Caller
- Register auf Stack
- Rücksprungadresse auf Stack
- Parameter in umgekehrter Reihenfolge auf Stack
- Prolog Callee
- Parameter vom Stack holen
- Epilog Callee
- Rücksprungadresse von Stack
- Ergebnis seiner Berechnung auf den Stack
- Epilog Caller
- Ergebnis vom Stack
- Register vom Stack und zurüsckschreiben
Aufgabe 3 d)
nach Prolog des HP als caller
| register |
| 1004 (Rücksprungadresse) |
| 3 (Parameter) |
| 2 (Parameter) |
nach Prolog des UP1 als Callee
| register |
| 1004 (Rücksprungadresse) |
nach Prolog von UP1 als Caller
| register |
| 1004 (Rücksprungadresse) |
| register |
| 4004 (Rücksprungadresse) |
| 3 |
| 1 |
nach Prolog von UP2 als Callee
| register |
| 1004 |
| register |
| 4004 |
nach Prolog von UP2 als caller
| register |
| 1004 |
| register |
| 4004 |
| register |
| 4004 |
| 3 |
| 0 |
nach Prolog von UP3 als Callee
| register |
| 1004 |
| register |
| 4004 |
| register |
| 4004 |
nach epilogue von UP3 als callee
| register |
| 1004 |
| register |
| 4004 |
| register |
| 0 |
nach epilogue von UP2 als caller
| register |
| 1004 |
| register |
| 4004 |
nach epilogue von UP2 als callee
| register |
| 1004 |
| register |
| 3 |
nach epilogue von UP1 als caller
| register |
| 1004 |
nach epilogue von UP1 als callee
| register |
| 6 |
nach epilogue von HP als caller
Aufgabe 5
a) falsch (s.S. 4)
b) wahr (s.S. 5)
c) wahr (s.S. 5)
d) wahr (s.S. 43)
e) falsch (s.S. 9)!!!
Aufgabe 6
a) Multiprogramming, logischer Mehrprogrammbetrieb, also die pseudoparaööeöe/verzahnte Ausführung von Prozessen.
b) Hauptvorteil: Effizienssteigerung
der Prozessor kann einen anderen Prozess bearbeiten, wenn der aktuelle auf z.B. E/A wartet.
c) Multiprocessoring: Echt parallele Ausführung von Prozessen auf verschiedenen Prozessoren
(+) Erhöhung der Rechenleistung ohne Verdopplung der Peripherie
(+) Schneller als Multiprogramming
(-) Komplexer für den Programmierer
(-) Betriebssystem muss entsprechend seine Scheduling-Algorithmen anpassen können
Aufgabe 7
a) sehr hohe Redundanz, hoher Wartungsaufwand, Programmcode wird länger, Rekursion nicht möglich.
b)Aufrufe geschlossener Unterprogramme erfordern Sprünge, Parameterübergabe, Sicherung, Wiederherstellung des Kontexts usw.
c) Call-by-Value: die Wert an sich
Call-by-Reference: Speicheradresse wird übergeben → Referenz/Zeiger
d) Mit dem Sprungbefehr wird die Adresse der aufzurufenden Sequenz in den Programm Counter geschrieben.
e) bei JMP wird „nur“ gesprungen, bei CALL wird zusätzlich die Rücksprungadresse auf den Stack oder ein Register gelegt.
f) Zwei Möglichkeiten:
- Sichern der Rücksprungadresse (RA) in einem speziellem Register.
- Ablegen auf den Stack.
Aufgabe 8
| Adresse | Befehl | Kommentar | Nach der Befehlsausführung | |||||
|---|---|---|---|---|---|---|---|---|
| PC | RA | SP | R1 | R2 | R3 | |||
| - | - | - | 405 | null | null | 23 | 42 | null |
| 405 | PUSH R1 | Sichern der CPU Register | 406 | null | 0 | 23 | 42 | null |
| 406 | PUSH R2 | 407 | null | 1 | 23 | 42 | null | |
| 407 | PUSH p3 | Platz für Ergebniss reservieren (p3=irgendwas) | 408 | null | 2 | 23 | 42 | null |
| 408 | PUSH p2 | Parameter rückwerts auf den Stack pushen | 409 | null | 3 | 23 | 42 | null |
| 409 | PUSH p1 | 410 | null | 4 | 23 | 42 | null | |
| 410 | CALL 770 | Unterprogrammaufruf | 770 | 411 | 4 | 23 | 42 | null |
| 770 | POP R1 | Parameter holen | 771 | 411 | 3 | p1 | 42 | null |
| 771 | POP R2 | 772 | 411 | 2 | p1 | p2 | null | |
| 772 | POP R2 | Stack dekrementieren für ergebniss | 773 | 411 | 1 | p1 | p2 | p3 |
| Unterproigramm: Halt, Stop, Jetzt rechne ich | ||||||||
| 810 | PUSH R3 | Ergebniss auf den Stack pushen | 811 | 411 | 2 | p1 | p2 | p3' |
| 811 | RET | 411 | null | 2 | p1 | p2 | p3' | |
| 411 | POP R3 | Ergebniss vom Stack holen | 412 | null | 1 | p1 | p2 | p3' |
| 412 | POP R2 | Wiederherstellung der CPU Register | 413 | null | 0 | p1 | 42 | p3' |
| 413 | POP R1 | 414 | null | null | 23 | 42 | p3' | |
Aufgabe 9
(ai) Nicht erglaubt: Prozess muss immer erst in den Ready Zustand wechseln, bevor er ausgeführt werden kann.
(aii) Erlaubt: Der Prozess wartet auf dein Ergebnis
(aiii) Nicht erlaubt: Ohne Ausführung kann ekin Ereigniss eintreten, auf das er warten müsste
(bi)
- new → ready: Programm wurde gestartet. Prozessimage ist komplett im Speicher, Prozess ist rechenbereit.
- Rest: Siehe script Seite 38
(bii) Ready-Zustand kann eingespart werden, da Prozesse Komplett unterbrechungsfrei abgearbeitet werden. Blocked zustand wird weiterhin benötigt, da manche Prozesse auf E/As warten.
(biii) Es ändert sich gar nichts, da das Model nur einen Prozess beschreibt
(bii)
Aufgabe 10
a) Skript S. 38/39.
b)
- Nachteil: eine hohe Anzahl von Zuständen kann sich negativ auf die Effizienz des Systems auswirken. Je mehr Zustände desto mehr Verwaltungsaufwand.
- Vorteil: durch Hinzunahme von Zuständen können aber auch Resources effizienter genutzt werden, etwa wichtige (höhere Priorität) Prozesse im Hauptspeicher gehalten werden, andere ausgelagert.
c)
- Scheduler: Wählt nächsten auszuführenden Prozess aus.
- Dispatcher: Ordnet dem Prozessor den nächsten auszuführenden Prozess zu.
Aufgabe 11
a)ready suspend to ready - blocked suspend to blocked: Freie Resourcen auf dem Hauptspeicher → Laden..
ready to ready suspend - blocked to blocked suspend: Der Hauptspeicher ist ausgelastet, Prozesse werden ausgelagert.
blocked suspend to ready suspend - blocked to ready: Das Ergebniss, auf das der Prozess gewartet hat, tritt ein.
b) i) falsch - enter, dispatch, suspend, exit
ii) falsch - Timeout: Die Zeit, die der Prozess zum Rechnen zugewiesen bekommen hat, ist abgelaufen.
iii) wahr
iv) wahr
v) falsch - der Prozesskontrollblock ist Teil des Prozessdeskriptors.
Prozessdeskriptor: Zusätzliche Information zu einem Prozess. Aka Prozess-Image. Siehe S 50 Skript?
Aufgabe 12
a)
i) Wahr
ii) Falsch
iii) Wahr
iv) Flasch. Bei Stack haben wir nur auf den obersten Element Zugriffe.
b) Skript S.47-49.
Prozessidentifikation (PID, PPID, …) wird benötigt um den Prozess referenieren zu können.
Prozesszustandsinformation (Nutzerregister, PC, SP) wird benötigt um einen Prozess nach einer Unterbrechung wieder herzustellen.
Prozesskontrollinformationen (Prozesszustand, Priorität, bisherige Rechenzeit) wird benötigt um den Prozess entsprechend der angewandten Schedulingstrategie korrekt zu Schedulen
c) PCB: enthält die für das Betriebsystem relevanten (kontroll-)Informationen zu einem Prozess.
Prozess-Image: bezeichet die Gesamtheit der physischen Bestandteile eines Prozesses.
Aufgabe 13
a) Moduswechsel: Wechsel zwischen System- und Nutzermodus oder umgekehrt.
b) Programmstatuswort: PSW
- Sicherung des Nutzerregisters
- Stackpointer
- Kontroll- und Statusregister (zB Carryflag, Overflowflag)
c) Kontextswitch: Sicherung und Wiederherstellung des Kontextes von „alten“ und neuem Prozess.
d) Aktualisierung und Sicherung des PCB, als:
- Zustandsinformationen (PSW, CPU-Register)
- Kontrollinformationen (Schedulinginfo)
Einfügen des PCB in die Warteschlange des Schedulers.
Selektion des nächsten auszuführenden Porzesses.
(Wieder)herstellung des kontextes des neuen Prozesses.
e) Anzahl der (CPU-)Register
f) i) zB Unterbrechungsbehandlungsroutinen, also Vorgänge in der BS-Aufrufe benötigt werden, zB Ausgabe auf den Bildschirm.
ii) Der Scheduler setzt den Status eines Prozesses von running auf ready und wählt einen anderen Prozess zur Azsführung aus.
iii) Beenden eines Prozesses → Unterbrechungsbehandlung und anschließend wechsel zu einem anderen Nutzerprozess.
Frage: Wer schedult den Scheduler?
g) Eher schlechte Idee - Der gewählte Ansatz verfolgt kurzfristige Ziele Änderungen von Anwendungen können auch den Bedarf von mehr Registern rechtfertigen.
Okay für Ampeln die immer nur Rot-Grun-Geld können, aber unfug sobald die Ampel zB auch noch Töne kennen soll.
Aufgabe 14
a) Skript S.43/44.
- Speichertabelle: Verwaltung von Haupt- & virtuellem Speicher
- I/O-Tabelle: Verwaltung von I/O-Geräten und Kanälen des Computersystems
- Dateitabellen: Verwalten von Informationen über die Existenz von Daten, deren Speicherort im Hintergrundspeicher, aktuellen Status und Atribute
- Prozesstabellen: entahlten Informationen zur Verwaltung von allen Prozessen im System
b) Es gibt Querbezüge: Speicher, E/A-Geräte, Dateien werden für einzelne Prozesse verwaltet.
Es bestehen Querbeziehungen z.B. zwischen I/O-Tabelle und Prozesstabelle.
Ein Prozess benutzt ein Gerät/Kanal und das muss irgendwo vermerkt werden.
c)
- Prozessrealisierung
- Prozessatribute
Für die Prozesslokalisierung wird das Prozess-Image verwendet. Das besteht aus dem auszuführenden Programm, Nutzerdaten, Stack und PCB, der die Attribute enthält.
Aufgabe 16
a) Wechsel von Benutzer- in Systemmodus
b)
- Sicherung vdes Programmkontext, also Nutzerregister, Stackpointer, Kontroll- & Statusregiser (z.B. PC)
- PC auf Adresse der durchzuführenden Routine setzen
- Wechsel durchführen
c) Wechsel eines Prozesses, also die vollständige Kontextsicherung des aktuellen und Kontextaktualisierung und wiederherstellung eines neuen Prozesses.
d)
- Aktualisierung und Sicherung des PCB des aktuellen Prozesses
- PCB dieses Prozesses in die Warteschlange des Schedulers einfügen
- Auswahl des nächsten auszuführenden Prozesses
- Wiederherstellung und Aktualisierung des PCB des neuen Prozesses
e)
Anzahl der Register
f i)
nur Moduswechsel: Systemaufruf, danach wird zum Prozess zurückgekehrt.
f ii)
nur Kontextwechsel: Prozesswechsel durch Zustandswechsel. Bei manchen Betriebssystemen sind Prozesswechsel keine Systemfunktionen, ein Prozess kann also, wenn er z.B. von running auf ready wehcselt, dies ohne Moduswechsel tun.
f iii)
Moduswechsel mit Kontextswitch: aktueller Prozess hat Unterbrechungsbehandlung ausgeführt und kann danach nicht weiter ausgeführt werden. Es wird zu einem neuen Prozess gewechselt.
g)
Schlechte Idee, da hier nur kurzfristig Zeit ….
Aufgabe 17
a) Ansonsten würde die gesamte Anwendung bis zur Beendung der Berechnung blockiert
b)
| User-Level | Kernel-Level | Prozess | |
|---|---|---|---|
| Generierung | Gering kein Aufruf von Systemroutinen. Etwas Verwaltungsaufwand innerhalb der Anwendung | Mittel Man benötigt bereits Systemroutinen, muss aber kein komplettes Porzessimage erstellen | Hoch es muss auf Systemroutinen zugegriffen werden. Zusätlich muss neuer Speicher allokiert werden und ein neuer Prozess erzeugt werden |
| Kommunikation und Datenaustausch | einfach und effizient: direkter Zugriff auf den gemeinsamen Speicher. | Same as User-Level. | Interprozesskommunikation, da kein gemeinsamer Speicherbereich vorhanden ist. |
| Scheduling | Übernimmt das Anwendungsprogramm. | Betriebssystem. | Betriebssystem. |
| Multiprozessingplattform | kein Nutzen. | möglich. | möglich. |
c) zur Berechnung erscheinen Kernel-Level-Threads am Sinnvollsten.
- echte Parallelität nutzbar.
- relativ geringer Aufwand bei der Generierung.
- einfache kommunikation.
KLT
- (+) realativ wenig Aufwand beim Erstellen
- (+) einfacher Datenaustausch
- (+) kein eigenen Schedulingalgorithmen nötig
- (+) Performanzgewinn auf Multiprozessorsystemen
ULT
- (-) Kein Multiprocessoring
- (-) eigener Schedulingalgorithmus
Prozess
- (-) hoher Aufwand
- (-) Interprozesskommunikation nötig
Aufgabe 18
a)
- (-) Hoher Synchronisationsaufwand, je mehr Threads, desto schwieriger das Synchronisieren & Debuggen.
- (-) Hoher Verwaltungsoverhead: Zeit und Rechnerpower gehen für Threadwechsel anstatt für die eigentliche Berechnung drauf.
b)
- (+) verschiedene Threads des gleichen Prozesses können echt parallel ausgeführt werden
- (+) einfacher Datenaustausch zwischen den einzelnen Threads eines Prozesses (dageteilterSpeicherbereich)
Aufgabe 19
Es gibt folgende Zustände
- new
- ready to run
- blocked
- running
Folgende Translationen werden durch Funktionen durchgeführt
- new →
start()→ ready to run - running →
yield()→ ready to run - running →
join()→ blocked - running →
sleep()→ blocked - running →
wait()→ blocked - blocked →
notify()→ ready to run - blocked →
notifyAll()→ reasdy to run
yield(): Thread gibt freiwillig seine Rechenzeit ab.sleep()vs.wait():sleep(time)wartet eine bestimmte Zeit, wird dann wieder automatisch „read to run“.wait()wartet aufnotify(),notifyAll(), muss also „außen“ wieder aktiviert werden.
Aufgabe 20
a) Es gibt follgete Zustände
- blocked
- ready to run
- running
- dead
Folgende translationen werderen durch funktionen durchgefürt
- ready to run → Scheduller wählt Prozess aus → running
- running → Prozess hat Zeitquantum abgearbeitet → ready to run
- running → I/O Operationen → blocked
- running → syncronisierter code noch nicht freigegeben → blocked
- running →
rund()-Methode fertig → daed - blocked → I/O Operation fertig → ready to run
- blocked →
sleep()beendet → ready to run - blocked →
join()beendet → ready to run - blocked → Syncronisierter code wird freigegeben → ready to run
b) heute: Kernel-Level-Threads früher: User-Level-Threads, wegen Platformunabhängigkeit. Nicht jedes BS auf dem Java lief hat KLTs angeboten
Aufgabe 21
T: Mittlere Bedienzeit (Zwit, die ein Prozess bis zur Abarbeitung im Zustand running verbringt)
S: Overhead für Prozesswechsel
Q: Größe der Zeitscheibe
P: T/T_{eff} = T / {T+n*S}
n = \ceil T/ Q
b)
* Q > T
n = \ceil T / Q = 1
p = T / {T+S}
⇒ Entartung zu FCFS, da jeder Prozess komplett zu Ende rechnen kann
Q = S « T
p = T / {T+{\ceil T / S} * S = T \ {2*T} = 0,5
* Q \aprox 0 ( Q → 0 )
\lim_{Q → 0} \ceil {T / Q} = \infty
\lim_{n → \infty} T / {T+n*S} = 0
c)
- Q nicht zu groß, um schnelle Antwortzeiten zu garantieren
- Q nicht zu klein wählen, da ansonsten CPU-Auslastung sinlos
- Q > Dauer des Swap-Prozesses
- * BSD 4.3: S = 5ms ; Q = 100ms
Aufgabe 22
„Trifft ein Prozess zum zeitpunkt t ein, so wird er direkt zum zum zeitpunkt t beachtet“ bedeutet, das er da in die Queu kommt, nicht den anderen unterbricht.
Aufgabe 23
siehe Blatt
Aufgabe 24
Erster Teil, siehe Blatt
d)
Zwei Prozesse: A und B
Betriebsmittel: X, Y und Z
t_{ij}: Zeitdauer, die BM_i von Prozess j benötigt wird
t_j: Dauer fpr Prozess j
kein Deadlock wenn: t_{XA} + t_{YA} + t_{ZA} < t_A und t_{XB} + t_{YB} + t_{ZB} < t_B
kein Deadlock wenn: t_{XA} * t_{XB} + t_{YA} * t_{YB} + t_{ZA} * t_{ZB} < t_{A} * t_{B}
Deadklock immer wenn: t_{XA} + t_{YA} + t_{ZA} > t_A und t_{XB} + t_{YB} + t_{ZB} > t_B
Deadlock immer wenn: siehe Angabe … Fuuu
Alle Aussagen falsch
Aufgabe 25
siehe blatt
Aufgabe 27
a)
Es kann ein deadlock auftreten, da alles synchronices ist.
b)
T1: a.swapContent(b); T2: b.swapContent(a);
c)
System.identityHashcode(Object);
public void swapContent(Box other) {
if(this == other) { // Don't swap the same objects
return;
}
else if(System.identityHashcode(this) < System.identityHashcode(other)) {
this.doSwapContent(other);
}
else {
other.doSwapContent(this);
}
}
Aufgabe 32
a) 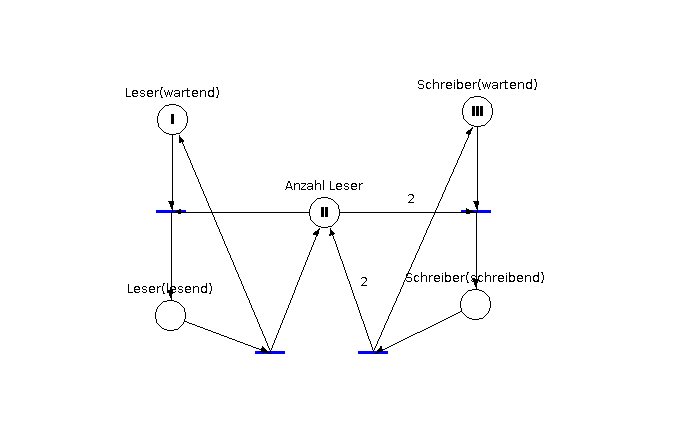
b) Mi(Leser(wartend), Leser(lesend), Anzahl Leser, Schreiber(wartend), Schreiber(schreibend))
M0(3,0,2,3,0)
↔
M1(2,1,1,3,0) M3(3,0,0,2,1)
↔
M2(1,2,0,3,0)
c) Der Petrinetz ist nicht fair. Wenn stetig Leseprozesse eintreten, können Schreibeprozesse nie abgearbeitet werden.
Die Lösung wäre, Schreibprozesse höher zu priorisieren.
Aufgabe 33
Algorithmus von Peterson
a) Druckaufträge können verloren gehen.
| aktiver Prozess | auseführte Codezeile | Inhalt von W | Wert von next |
|---|---|---|---|
| p1 | 2 | prt_file1 | 0 |
| p2 | 2 | prt_file2 | 0 |
| p1 | 3 | prt_file2 | 1 |
| p2 | 3 | prt_file2 | 2 |
b) For p1:
a = true //I want
y = 1 //You may
while (y = 1 && b = true){
//do nothing
}
W[next] …
…
a = false
For p2:
b= true
y = 0
while (y = 0 && b = true){
//do nothing
}
W[next] …
…
b = false
c) busy-waiting: Der Peterson-Ansatz verschwendet CPU Zeit. Ein Prozess, dem der Eintritt in den kritischen Bereich verwährt wurde, muss in seiner Schleife selbst prüfen wann er dran ist.
Aufgabe 34
a) Semaphore ist eine Kontrollkomponente
- atomare Prolog- & Epilogoperationen
- eine Zählvariable
Die Zählvariable gibt an wie viele Prozesse noch in den kritischen Bereich eintreten dürfen, bzw. wie viele Prozesse auf den Eintritt warten. - einen Warteraum für Prozess mit blockieren- & endblockierenoperationen
init(Semaphor, Anfangswert)- setzt die Zählvariable der Semaphore auf ausgangswert.- p-Operation (Prolog,
wait(),down())- die Zählvariable wird um eins verringert
- danach:
- Zählvariable >= 0 → Prozess kann weitermachen
- Zählvariable < 0 →Prozess kommt in den Warteraum
S–; if(S < 0) { Prozess in warteschlange an stelle -S ; }
- v-Operation (Epilog operation,
signal(),up())- Zählvariable wird um eins erhöht
- danach:
- Zählvariable > 0 → kein wartender Prozess
- Zählvariable ⇐ 0 → am längsten wartenden Prozess entblokieren
S++; if(S⇐ 0) { Setze den am längsten wartenden Prozess auf „rechnend“ ; }- Kann aufgerufen werden, ohne vorheriges
p()!
b) Anzahl der Prozesse, die gleichzeitig in ihre kritische Phase eintreten dürfen. (Anzhal der Prozesse die hintereinader die Prolog operation ausführen können, ohne blokiert zu werden)
c) Bei einer Vertauschung von 3) und 4) in P1 wäre nicht mehr gewährleistet, dass P1 vor Belegung des Semaphors S überprüft, ob Platz >= 0 ist.
Ist dies nicht der Fall, kann P2 nämlich nicht in seinen kritischen Bereich eintreten.
Ist der Semaphor S aber von P1 belegt, dann kann P2 ebenfals nicht in seinen kritischen Bereich eintrten und Platz nicht erhöhen ⇒ Deadlock
d) ka wo das hingehört
P1 1 S=0 P1 2 platz=-1 -> blockiert P2 1 P2 2 s=-1 -> blockiert
init(S, 1) init(platz, 0) init(bestand, 5) P1: wait(S) -> S=0, P1 macht weiter P1: wait(platz) -> platz = -1, P1 wird in die Warteschlange gesetzt P2: wait(bestand) -> bestand = 4, P2 macht weiter P2: wait(S) -> S = -1, P2 auf warteschlange
⇒ Deadlock
Aufgabe 35
- a) falsch
- b) falsch
- c) falsch
- d) wahr
Aufgabe 36
i)
init(x, 2) init(y, 0) init(z, 2) P1: 3 P1: 4 P3: 3 P3: 4
Es geht zwar noch ein paar Zeilen weiter, aber es ist ab hier der deadlock sicher. ⇒ Kein Prozess rechnet zu Ende.
ii)
init(x, 3) init(y, 0) init(z, 2) P1: 3 P1: 4 P1: 5 P1: 7 P2: 3 P2: 5 P2: 6 P3: 3 P3: 4 P3: 5 P3: 7 P3: 8
iii)
init(x, 3) init(y, 0) init(z, 2) P1: 3 P1: 4 P2: 3 P2: 5 P2: 6 P1: 5 P1: 7 P3: 3 P3: 4
⇒ Deadlock. Nur P1 und P2 rechnen zu ende
iv)
init(x, 0) init(y, 0) init(z, 3) P3: 3 P3: 4 P3: 5 P3: 7 P3: 8 P2: 3 P2: 5 P2: 6 P1: 3
⇒ Deadlock. Nur P2 und P3 kommen zu einem Ende.
Aufgabe 37
To be scanned
Aufgabe 39
a. Lockmechanismus mit Warteschlange.
Jedem Objekt wird ein Lock zugeordnet. Ein Threat kann nur dann auf eine synchornised-Methode eines Objekts zugreifen, wen dieses verfügbar ist.
Das Lock wird bei Verlasssen der synchronized-Methode wieder freigegeben.
b. wait() und notifyAll().
c. Bei „echten“ Monitoren werden Klassen synchronisiert, in Java Objekte bzw. Methoden dieser Objekte (public variablen können immer noch von außen bösartig verändert werden).
d. Der wesentliche Unterschied besteht im Fehlen von Bedingungs-Variablen, konkret wäre ein Aufruf von wait(Bedingung) nicht möglich.
e.
- Für jede Bedingun ein eigenes Syncronisationsobjekt nutzen.
- (-) viele Objekte, Mehraufwand bei Syncronisation & nicht immer einsetzbar.
- Man verwendet ein notifyAll(), um alle Threads aufzuwecken
- (-) Ineffizient, da jeder Thread dann selber testen muss, ob seine Bedingung inzwischen erfüllt ist.
f. Signal and continue.
Aufgabe 40
War mal Klausuraufgabe
a. wahr
b. falsch
c. falsch
d. falsch
e. falsch
Aufgabe 41
Aufgabe 42
receive(): queue.remove(i); print(); return.message; … wait();
send(): notifyAll();
run(): String message = box.recieve(this.type);
Aufgabe 43
a) Statische Speichergrpartitionierung
- feste Blöcke gleicher (oder unterschiedlicher, aber nicht variabler) Größe
- Seitenersetzung (Paging): Daten werden in Seiten (Pages) geladen, die bei Bedarf in die entsprechenden Rahmen im Hauptspeicher geladen werden
- Frage: Welche Seiten sollen verdrängt werden, wenn der Speicher voll ist, aber neue Daten im Speicher geladen werden sollen? (Auslagerung Seitenersetzung) ←- ??? wo gehört das hin
- Seiten ersetungsstrategieen
- FIFO
- LIFO
- LRU (Least recently used)
- LFU (Least frequently used)
- Second chance
- Probleme: interne Fragmentierung
b)
- Blöcke variabler größe
- Zusammengehörige Daten werden als einer bestimmten Stelle …
Aufgabe 44
a)
- P1: 100kB
- P2: 420kB
- P3: 250kB
- P4: 60kB
Baum following shortly.
b) In den belegten Segmenten entstehen - Freibereiche, da die Prozesse die Segmente nicht voll ausfüllen.
→ interne Fragmentierung
Insgesamt stehen nur noch 320kB Speicher zu verfügung
c) P5 kann nicht mehr geladen werden, da kein 512kB großes Segment zu verfügung Steht (und 356kB nicht ausreichen).
d) Das Buddy-Verfahren kombiniert die Vorteile fester Partitionierung mit den Vorteilen der dynamischen (einfache Adressierung & Flexibilität) insbesondere bei vielen kleinen Anfragen kommt es zu weniger internen Fragmentierung als bei fester Partitionierung.
Aufgabe 46
a) i)
- Größe des physischen Speichers: 32 KB
- Größe des virtuellen Speichers: 64 KB
- Größe von Seiten und Seitenrahmen: 4 KB
- Wortgröße: 1 Byte
Virtueller Speicher mit 16 „Schubladen“. Durchnumeriert von 0000 zu 1111.
Physischer Speicher mit 8 „Schubladen“. Durchnumeriert von 000 zu 111.
Skizze Folgt.
ii)
- 4 Bits für die Seitennummer (virtueller Adressraum)
- 8 Buts für die Seitennummer (physischer Adressraum
- 12 Bits für Offset (log2(4096Byte))
Offset: Portion/Byte innerhalb einer Seite
iii) 8196_10 = 0010 0000 0000 0100_L
b) 1 Byte Wortgröße, 12 des 32 Adressbits werden für den Offset benützt.
2^32/2^12 = 2^20 = 1.048.576
→ Daraus ergibt sich die maximale Größe des HS: 4GB
Der physische Speicher ist immer eine Teilmenge des virtuellen Speichers. Ziel ist es ja, den Prozesssen einen linearen Speicher dynamischer Größe zu Verfügung zu stellen.
c) Lösung: Mehrstufige Seitentabelle.
- Erste 10Bits (Pt1) für die erste Stufe
- Zweite 10 Bits für die zweite Stufe
- wide 12 Bits für den Offset
Aufgabe 48
a) i) DS, BS
ii) FS, BS
iii) DS, BS
b) i) First, Next
ii) Best, Worst
iii) Best
iv) First
c) Anzahl der Seitenfehler: 12 Stellen
d) 512kB großer Speicher, 2kB minimaler Segment.
→ 523/2 = 256 → 8 Bits