Inhaltsverzeichnis
Prozesse
Programme und Unterprogramme
Programm -> Mscgienenprogramm
Wiederholung:
Abarbeitung von Maschienenbefehlen
- Speicher: lineares Array von Information Einheiten
- Speicherzelle: kleinste adressierbare Speichereinheit
- Speicherkapazität: m*n^n = 1byte*2^32 = 4GB
- n = Länge der Adresse
- m = Länge/Breite einer Speicherzelle
- CPU
- Datenprozessor [von Datenbuss]
- MBR = Memory Buffer Register [von
- IR = Instruction Register
- Befehlsprozessor [zu Adressbus]
- PC = Programmcounter (n)
- MAR = Memory Adress Register (n) [von PC]
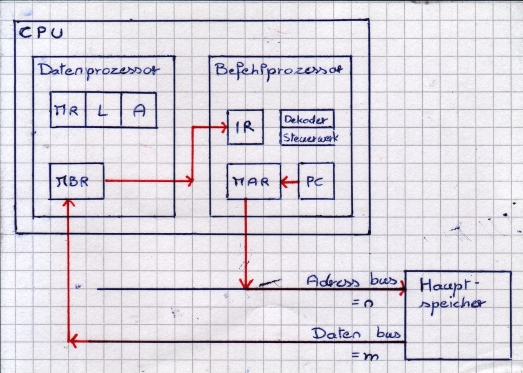
Abarbeitung von Machinenprogram:
- MAR ← PC
- MBR ← S[MAR]
- IR ← MBR
- decode(IR)
- if not „Sprungebefehl“ then
- _<stelle operanden bereit>
- _PC ← PC + 1
- else
- _PC ← Sprungadresse
- end
Unterprogramme und Prozeduren
Problem: Oft gleiche/ähnlche Abläufe
- Offene Unterprogramme (Strg + C & Strg + V)
- Fehleranfällig
- Mühsam
- Höchstens bei x^2, |x|, …
- Gesclossene Unterprogramme (Prozedur)
- Programmstück wird über Anfangsadresse angesprungen (Addresse der speicherzelle, mit der es beginnt)
- Anouncement (A → B)
- Invocation (A → B dann B → A)
Kommunikation erfolgt wie:- Stack
- Zugriff von oben, oberste Adresse ist 0, unterste 2^(n-1)
- Spezielle Register
Die Befehle CALL & RET
2 Dinge unterscheiden
- Sprungbefehl JMP
COMMAND JMP addr
BEGIN
_ PC ← addr
END - Prozeduraufruf
Sprung wie oben + Sicherung des Rücksprungs- Stack
- COMMAND CALL addr
BEGIN
_ PUSH(PC + 1)
PC ← addr
END - COMMAND RET
BEGIN
_ PC ← POP
END
- Register
- COMMAND CALL addr
BEGIN
_ RA ← PC + 1
_ PC ← addr
END - COMMAND RET
BEGIN
_ PC ← RA
END
Unterprogrammaufrufe
HP: ... 4000 ... ... 4100 CALL 4500 4101 ... Prozedur 1: 4500 ... ... 4600 CALL 4800 4601 ... ... 4650 CALL 4800 4651 ... ... 4700 RET Prozedur 2. 4800 ... ... 4890 RET
Module
- Unterprogramme (Prozeduren, Funktionen)
- Komponenten eines BS / BS als Ganzes
- Nuzerprogramme
- Prozesse
Realisierung eines UP-Aufrufs
Modell-Maschiene
- PC
- SP
- 16 Register (R0 bis R15; R15 vorbelegt)
- R12 Ablageadresse des ersten Parameters
- R13 Basisadresse des lokalen Datenraums des Unterprograms
Stack baut sich auf:
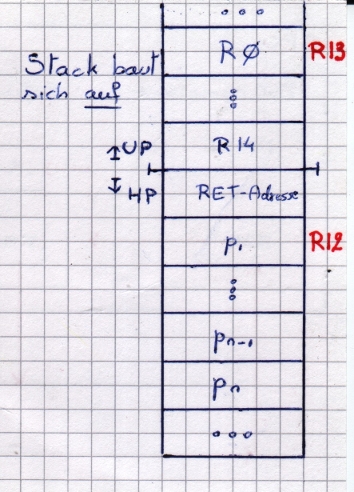
HP:
4000 ...
...
40?? PUSH pn
...
4098 PUSH p2
4099 PUSH p1
4100 CALL 4500
4101 POP p1
4102 POP p2
...
41?? POP pn
Prozedur:
4500 PUSH // Alle Register R14 to R0 auf Stack
4501 MOVE 64+SP, R12 //p1 in R12
4502 MOVE SP, R13
... <up>
???? MOVE R13, SP
POP R
RET
Rekursive Prozeduraufrufe
PROCEDURE fak(k:INT) RETURNS INT BEGIN IF k=0 THEN RETURN 1 ELSE RETURN k*fak(k-1) END
(3) Prozess
| Name | Wie | Was |
|---|---|---|
| Programm | Statisch | Code |
| Prozess | Dynamisch | Programm in Ausführung → Im Speicher → Eigener Kontext |
- Prozesskontext: Um Prozess auf dem selben Rechner fortzuführen
- Prozessimage: Um Prozess auf anderem Rechner zu starten
Arten (paralleler) Ausführung:
- Uniprogramming: Nacheinander (auch keine Unterbrechung bei warten auf I/O)
- Multiprogramming: pseudo-parallel
- Multiprocessoring: echt-parallel
Multiprogramming rechnungen (!) Siehe script S. 30
Fork/Prozesshierachie

Prozess erzeugen
- PID erzeugen
- Speicher reservieren
- PCB erzeugen
- In Scheduller queues eintragen
- Sonstige Datenstrukturen erzeugen
2-Zustands Prozessmodell
- Not running
- running
5-Zustands Prozessmodell
- ready (queue)
- running
- blocked (queue)
- new
- exit
7-Zustands Prozessmodell
- ready
- running
- blocked
- ready, suspend
- blocked, suspend
- new
- exit

Tabellen
- Seiten/Speicher Tabellen
- Freier Hauptspeicher
- Freier Virtueller Speicher
- Prozess → Virtueller Speicher
- Virtueller Speicher → Hauptspeicher
- Schutzatribute
- I/O Tabellen
- Geräte Status
- Geräte Zuordnung
- mmap
- Datei Tabellen
- Prozess Tabellen
- PCB
- Prozesslokalisierung
- Prozessdeskriptor
- Prozessadressraum / lokalisierung
- PCB
PCB
- Prozessidentifikation
- PID
- PPID
- UID
- Prozesszustandsinformationen
- Register
- PSW (Programm Status Word)
- Prozesskontrollinformationen
- Scheduler Infos
- ready/blocked/running/…
- Priorität
- Erwartete Ereignisse
- Sonstige Scheduler Atribute
- Nächste PID (linked list)
- Signale (IPC)
- Nachrichten (IPC)
- Rechte
Kontextswitch
- Update PCB des alten Prozesses
- Alten Prozess in Queue des Schedulers einfügen
- Scheduler wählt neuen Prozess
- Wiederherstellen des PCB des neuen Prozesses
Modus
- Systemmodus / Kernel mode
- Nutzermodus / User mode (Eingeschränkt ⇒ Support-Funktion des OS verwenden a.k.a. Syscall)
Aktueller Modus steht in PSW (Programm Status Word)
- Update des PCB (nicht vollständig)
- Privilegien Ändern
- Sprung zu Unterbrechungsroutine
Unterbrechung
Bei
- Externe Unterbrechungen (Interrupt)
z.B. I/O - Interne Unterbrechungen (Exceptions/Traps)
z.B. Fehler - Unterbrechungsroutine (Interrupt Handler)
Eine OS funktion
Unterbrechungskonflikte
Lösung: Prioritäten
IPL (Interrupt Priority Level) Teil des PSW (Programm Status Word)
(4) Threads
- Prozess
Eigentümer/Verwalter von Resourcen - Thread / lightweight process
Aufgabe abarbeiten
Pro Thread
- TCB
- User Stack
- Kernel Stack
Zustände
- Ready
- Running
- Blocked
- (alles andere sinnlos
Arten
- ULT (User level threads)
- (+) Keine speziellen Rechte
- (+) Eigener angepasster Scheduler
- (+) Keine OS anforderungen
- (-) Einer blokiert ⇒ Alle blokiert
- (-) Nutzt nur einen Kern
- KLT (Kernel level threads)
- (+) Einer blokiert ⇒ Anderer running
- (+) Nutzt alle Kerne
- (-) Moduswechsel für Threadwechsel nötig
- Kombiniert
| Threads | |||
|---|---|---|---|
| 1 | n | ||
| Prozesse | 1 | Klassisch | Normal |
| m | Thread kann Prozess wechseln z.B. Cloud | n:1 und 1:m kombiniert z.B. TRIX |
|
Java-Thread Modell
http://www.uml-diagrams.org/examples/java-6-thread-state-machine-diagram-example.html|Perfektes Diagramm (Zu beachten ist, das objekte noch eine lock- und wait-pool haben. Ein Thread ist BLOCKED wenn es im lock-pool eines objekts ist, indem es eine syncronizes pasage betreten will. Ein Thread ist *WAITING wenn es im wait-pool eines Objekts ist, indem es wait() in einem syncronized block aufgerufen hat (s. Monitor weiter unten).
Doku des Thread.State.
Advanced shit ⇒ Uninteresant:
http://en.wikipedia.org/wiki/Flynn's_taxonomy
| Single Data | Multiple Data | |
|---|---|---|
| Single Instruction | SISD (für Alte, normale CPUs | SIMD Normale CPUs mit SSE/3Dnow Vektorprozessoren / Arrayprozessoren |
| Multiple Instruction | MISD Fehlertolerante Rechner (Flugzeuge) | MIMD Normale Multicore CPUs Rechnerverbunde (Supercomputer) |
(5) Scheduling
Aufgabenverteilung
- Scheduler
Algorithmus der nächsten Prozess bestimmt - Displatcher
Programm was context switcht
3 Zustands Prozessmodell ⇒ Short Term Scheduling 5 Zustands Prozessmodell ⇒ Medium Term Scheduling 7 Zustands Prozessmodell ⇒ Long Term Scheduling
Scheduling Arten
- Nicht preemptiv (freiwillige kontrollabgabe möglich, z.B. bei warten auf I/O)
- FIFO/FCFS (First Come First Served)
- (+) Fair
- (+) Einfach
- SJF/SPN (Shortest Process Next)
- (+) Optimale mittlere Verweildauer
- (*) Vorsehung der Ausführungszeit?
- (-) Verhungern
- Preemptiv
- SRT/SRPT (Shortest Remaining Processing Time)
- (+) Theoretisch Optimal
- (-) Verhungern
- (!) (Neue) Kürzere Prozesse unterbrechen den laufenden
- RR (Round Robin) / Zeitscheibenverfahren
- (+) Kein Verhungern
- (+) Einfach
- (*) Mittlere Verweildauer ist OK
- PS (Priority Scheduling)
- (?) Der beschreibung nach eher nicht preemptiv????
- Multilevel Feedback Queueing
- Freiwillige abgabe ⇒ gleiche FIFO queue
- Timeout abgabe ⇒ nächst niedrigere FIFO queue
- Niedrigste queue: RR
Mittlere Verweildauer:
FCFS > RR > SRPT/SJF (best)
Allgemeine Anforderungen
- Fair
- Policy Enforcement (keine Ausnahmen)
- Balance (System auslasten)
- Datensicherheit
- Skalierbarket
- Effizienz (CPU auslasten)
System Arten / Anforderungen
- Batch
- Durchsatz
- Verweildauer
- Prozessorauslastung
- Interaktiv
- Antwortzeit
- Verhältnismäsigkeit
- Interaktion (Viele nutzer)
- Echtzeit
- Sollzeitpunkte
- Vorhersagbarkeit
Zeitpunkte
- Ankunftszeit (erstes ready)
- Beendigungszeit (erstes done)
- Startzeit (erstes running)
Zeitspannen
- Verweildauer (erstes ready - done)
- Bedienzeit (im zustand running)
- Wartezeit (nicht im zustand running)
- Normalisierte Verweildauer = Verweildauer / Bedienzeit (1 = gut, >1 schlechter)
Verweildauer = Bedienzeit + Wartezeit
- Antwortzeit (alternativ: Reaktionszeit auf Ereignisse)
- Remote
Antwortzeit > Verweildauer - Lokal
Antwortzeit = Verweildauer
- 1 Queue
- Queue pro Priorität
- Queue pro Priorität
Optimalitätsbeweis von SJF
| $n$ | Anzahl Jobs |
| $t_j$ | Ausführungszeit eines Jobs |
| $i_j$ | Permutation der Jobs |
Mittlere Verweildauer bei der Reihenfolge $t_{i_1}, t_{i_2}, \dots, t_{i_n}$ (← das ist doch keine Reihenfolge (?)) ist: \[ \frac{1}{n} (t_{i_1} + (t_{i_1} + t_{i_2}) + \cdots + (t_{i_1} + t_{i_2} + \cdots + t_{i_n})) = \frac{1}{n} \sum^n_{k=1}\sum^k_{j=1}t_{i_j} = \frac{1}{n} \sum^n_{k=1}(n-k+1)t_{i_k} \]
Das ist offensichtlich minimal wenn \[ n \cdot t_{i_1} + (n-1) \cdot t_{i_2} + \cdots + 2 \cdot t_{i_{n-1}} + 1 \cdot t_{i_{n-1}} = min \]
die ist schon wieder offensichtlich minimal wenn gilt: \[ t_{i_1} < t_{i_2} < \cdots < t_{i_{n-1}} < t_{i_n} \]
(6) Deadlocks
Prozessfortschrittsdiagramm
- unsicherer Bereich
- unmöglicher Bereich
Alle 4 Deadlockbedingungen müssen werfüllt sein
- Indirekte Methoden
- Mutal Exclusion
- Prozesse >= 2
- Exklusive resourcen >= 2
- Hold and Wait
- Mindestens 1 Resource besitzen
- weitere anfordern
- No Preemption (Resource kann nicht zwangsentzogen werden)
- Direkte Methoden
- Circular wait
Petrinetze
Begriffe
- Stellen
- Marken
- Kapazität
- Transitionen
- Aktiv
- Gefeuert
- Eingangskanten
- Ausgangskanten
- Gewicht
Default
- Kantengewicht: 1
- Stellenkapazität: \infty
Erreichbarkeitsgraph
- Verklemmungsfrei
Alles zyklisch - Partial deadlock/Teilweise Verklemung
Nicht alles erreichbar - deadlock/Verklemmung
Keine Nachfolger
deadlock ⇒ partial deadlock
Achtung: Werden mehere Marken eingesamelt, so werden dennoch nur eine (default) abgegeben.
Lösungen
- Umordnen
(7) Prozesskoordination
| Quasi Paralell | Parallel | |
|---|---|---|
| Unabhängige Abläufe | ||
| Abhängige Abläufe | Nebenläufigkeit |
Ablaufverhalten:
- Syncron
Vorbestimmt (ähnlich RTOS) - Asynchron
Ereignisgesteuert (Zufällig)
- Mutual exclusion
- Nur 1 Prozess im kritischen Bereich
- Progress
- Nur die Kandidaten entscheiden unter sich
- (Unbeeinflusst von Prozessen die nicht rein wollen)
- Bounded Waiting
- Jeder der will darf
- In endlicher Zeit
- ⇒ Wer im Kritischen bereich ist muss da wieder raus (dar z.B. nicht drinn sterben)
Busy waiting: while(not condition) { nop; }
Probleme
Erzeuger/Verbraucher

- 2 Semphore für Speicherplatz und 1 für Speicherzugriff = 3 Semaphonre
- Lösung mit
- Ringbuffer, wenn
- 1 Erzeuger
- 1 Verbraucher
- Mutex
Erzeuger
while(true) { el = clreate(); wait(out); wait(s); push(el); signal(s); signal(in); }
Verbraucher:
while(true) { wait(in); wait(s); pop(); signal(s); signal(out); }
Leser/Schreiber
- Es ist darauf zu achten das nicht ein leser/schreiber alle schreiber/leser blokieren kann
Philosophen
- Jeder Philosoph könnte sich ein Stäbchen nehmen ⇒ Keiner kann essen
- ⇒ Weiterer semaphore der Anzhal esser begrenzt
while(true) { wait(esser); wait(stäbchen[i]); wait(stäbchen[(i+1) % n]); essen(); signal(stäbchen[(i+1) % n]); signal(stäbchen[i]); signal(esser); }
Mutex algos
Algorithmus von Decker
- (-) Nur 2 Prozesse
flag[0] = true; // Ich will while (flag[1] == true) { // Solange der andere will oder tut if (turn ≠ 0) { // und ich bin nicht dran flag[0] = false; // ziehe mein "will" zurück, bis ich wieder dran bin while (turn ≠ 0) { // (so kann der andre aus der Äuseren Schleife raus) // busy wait } flag[0] = true; } } // <critical section> // ... // </critical section> turn = 1; flag[0] = false;
Nur 2 Prozesse!
Algorithmus von Petterson
- (+) Belibige Anzahl an Prozessen
/* claim the resource */ flags[i] = BUSY; /* give away the turn */ turn = j ; /* wait while the other process is using the resource *and* has the turn */ while ((flags[j] == BUSY) && (turn != i )) { } // <critical section> // ... // </critical section> /* release the resource */ flags[i] = FREE;
- http://en.wikipedia.org/wiki/Peterson's_algorithm
Interrupts disablen
- (-) Nicht für echte Paralelität
- (-) Im Userland unmöglich
- (+) Belibige Anzahl an Prozessen
Test and Set (int)
- Kein Bounded Waiting (scheduller kann ihn immer zurücksetzen).
- (+) Belibige Anzahl an Prozessen
Test and Set ist ein atomarer Maschienenbefehl.
bool testAndSet(int * i) { if(*i == 0) { *i = 1; return true; } else { *i = 1; return false; } }
| In | Out | |
|---|---|---|
i | i | return |
| 0 | 1 | true |
| 1 | 1 | false |
while(testAndSet(i) == false) { nop; } // <critical section> // ... // </critical section> i = 0;
Test and Set (bool)
- Kein Bounded Waiting (scheduller kann ihn immer zurücksetzen).
- (+) Belibige Anzahl an Prozessen
Test and Set ist ein atomarer Maschienenbefehl.
bool testAndSet(bool * lock) { bool old = *lock; *lock = true; return old; }
| In | Out | |
|---|---|---|
lock | lock | return |
| false | true | false |
| true | true | true |
while(testAndSet(lock) == true) { nop; } // <critical section> // ... // </critical section> lock = false;
Semaphor
- Warteschlange ⇒ Fair & kein busy waiting
signal()dekrementiert auch unter 0wait(S = 0)⇒ wait!- Trick:
init()mit 0 ⇒ Man kann auf etwas warten lasesen (syncronisation)
Monitor
- Bedingungen (nicht nur i > 0)
- Monitorprozeduren
wait()Aufruf ⇒ Ein anderer Thread darf in den selbe Monitor
- Lokale Daten
- Nur über Monitor Prozedur zugreifbar
cwait()csignal()
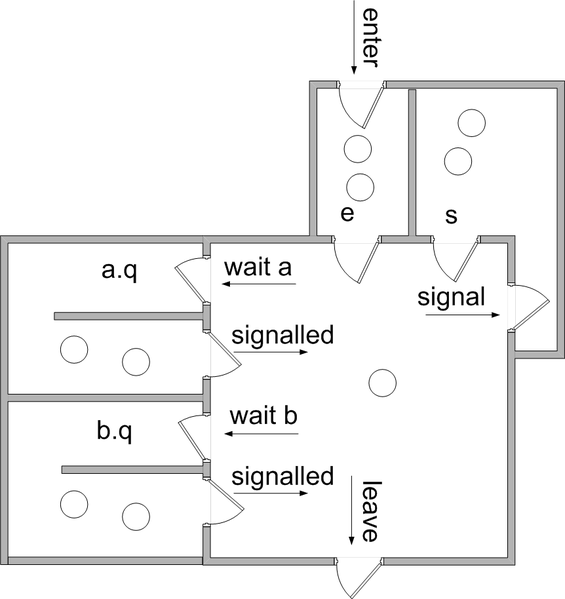
Java-Style
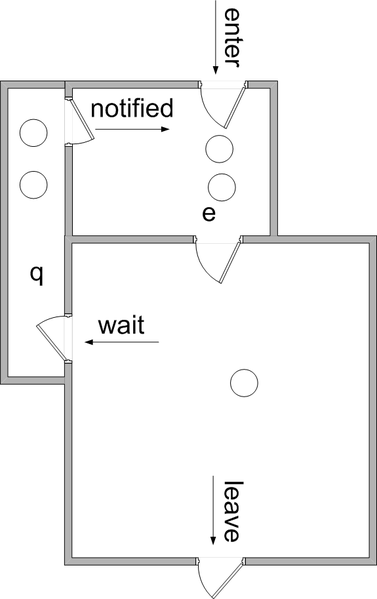
Messages
| Send | |||
|---|---|---|---|
| Blocking | Non Blocking | ||
| Receive | Blocking | Rendezvous | Post-Modell |
| Non Blocking | Mit/Ohne Buffer | ||
Adressierung
- Direkt
- Empfange von jedem
- Empfangsfilter (auf Prozesse)
- Indirekt (Queues)
- 1:1 …
- n:1 Ports
- 1:n Broadcasting
- n:m Mailbox
(8) Speicher
Speicherverwaltung
- Wiederauffinden
Wo habe ich was hingemapt / ausgelagert - Schutz
Kernel/User space - Teilen/Aufteilen
gleichelib - Logische Organisation
clusterung - Physische Organisation
kopieren beim paging
Fragmentierng
- Interne Fragmentierung
In einer Partition - Externe Fragmentierung
Zwischen den Partitionen
Speicherpartitionierung
- Feste Partitionierung (interne Fragmentierung)
- gleich große Partitionen
- unterschiedlich große Partitionen
- Dynamische Partitionierung (externe Fragmentierung)
- Best-Fit
Finde Platz im gesamten Speicher - First-Fit
Finde Platz von Anfang an - Next-Fit
finde Platz ab letztem Treffer
- Buddy Systeme (interne & externe Fragmentierung)
- Gewichtete Buddy systeme (interne & externe Fragmentierung)
Normale Buddy Systeme
$2^L \le 2^K \le 2^U \le 2^N$
- N (fix): gesamter Speicher
- U (fix): größter Block
- K: Variable Block Größe
- L (fix): kleinster Block
Entfernen: Rekursiver Merge!

Gewichtete Buddy Systeme
| Normal | 1:1 Split |
|---|---|
| Jetzt | $2^n$ ⇒ 1:3 split $3 \cdot 2^n$ ⇒ 1:2 split |
VM
| HGS | HS |
| Pages/Seiten | Frames/Seitenrahmen |
Adresstranslation
Seitentabelle

Paging (Vorlade) Strategien
- Demand Paging
Kein Vorladen - Demand Prepaging
Seitenfehler ⇒ Vorladen - Look-Ahead-Paging
Random bedingung ⇒ Vorladen
Paging Policies
- Resident Set Management Policy
Frame muss drinn bleiben - Fetch Policy
Frame Vorlade Strategie - Placement Policy
Irrelevant - Replacement Policy
- OPT
- FIFO
- LIFO
- LRU
- LFU
Zugriffe seit …- laden der Seite
- Zeit
- letztem Seitenfehler
- Climb
- Clock
- Working Set
OPT
Vorwärtsabstand: Löschen was am längsten nicht mehr gebraucht wird
FIFO
| Z | E | ||||
| Fr 1 | 3 | 3 | 4 | ||
| Fr 2 | 2 | 2 | 2 | 3 | |
| Fr 3 | 1 | 1 | 1 | 1 | 2 |
Zugriff: Nix Ersetzen: Durchdrücken
LRU
| Z | E | ||||
| Fr 1 | 3 | 2 | 4 | ||
| Fr 2 | 2 | 2 | 3 | 2 | |
| Fr 3 | 1 | 1 | 1 | 1 | 3 |
Zugriff: Ganz Hochzeihen Ersetzen: Durchdrücken
Bei: Starker Lokalität
Climb
| Z | E | ||||
| Fr 1 | 3 | 2 | 2 | ||
| Fr 2 | 2 | 2 | 3 | 3 | |
| Fr 3 | 1 | 1 | 1 | 1 | 4 |
Zugriff: Eins Hochbubblen Ersetzen: Unten austauschen
Clock
- Zeiger zeigt auf älterestes Element
- Use flag
- Neu: 1
- Zugriff: 1
- Zeiger überstreich: 0
- Zeiger löscht Use Bit 0
Working Set
W(t, h) = Menge der h letzten referenzierten Seiten, seit einschließlich t w(t, h) = | W(t, h) |
- h fix
- Jeder Prozess hat w(t, h) Pagages
- Ersetze was nicht in Workin set, sonst: Prozess auslagern
Bei: Starker Lokalität
Begriffe
Belady's Anomalie
FIFO: Mehr Seiten ⇒ ggf. mehr page faults
Reference String
Anforderungsreihenfolge der Pages
Distance String
Von wo eine zugegriffene Page hochgezogen wird (1-Indexiert)
| Ref. Str. | 2 | 3 | 1 | 3 | 3 |
|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 3 | 3 |
| 2 | 4 | 2 | 3 | 1 | 1 |
| 3 | 1 | 4 | 2 | 2 | 2 |
| 4 | 1 | 4 | 4 | 4 | |
| Dist. Str. | ? | ∞ | 4 | 2 | 1 |
Lifetime-Function L(m)
Mittlere Zeit zwischen Seitenfehlern
Stack Algorithmus
Mehr Frames ⇒ Anszahl an Seitenfehlern wird kleiner oder bleibt gleich
Anzhal Seitenfehler aus Distance String
- $C_k$ Anzahl an $k$ Elementen in Distance String
- $F_m$ Anzahl an Seitenfehlern
\[ F_m = \sum^n_{k=m+1} C_k + C_\infty \]